
Die glänzende Seite – Wenn Maschinen mitgestalten
Was heute Alltag ist, war vor ein paar Jahren noch Science-Fiction: Eine Maschine schreibt Gedichte, malt Bilder, komponiert Musik oder programmiert ganze Apps. Generative KI-Tools wie ChatGPT, Midjourney oder DALL·E sind für Millionen Menschen so selbstverständlich wie eine Suchmaschine. Generative KI kann aus einer vagen Idee in Sekunden ein ganzes Konzept zaubern; ein Logo, ein Songtext, ein Marketingtext oder die Struktur dieses Beitrags liefern. Sie bricht Barrieren auf, die bisher nur Profis überwinden konnten. Wer heute eine Idee hat, kann sie rasch umsetzen – ohne teures Studio, Agentur oder Programmierkurs. Für Designer:innen, Autor:innen und Entwickler:innen bieten sich Werkzeuge, die Ideen schneller zum Leben erwecken und kreative Blockaden überwinden. Auch in der Bildung eröffnen sich neue Möglichkeiten: personalisierte Lerninhalte, automatisierte Übersetzungen und interaktive Tutorensysteme. In der Wissenschaft unterstützt KI bei der Datenanalyse und beim Entwurf von Hypothesen. Kurz: Die Technologie kann Kreativität beflügeln und Wissen zugänglicher machen – vorausgesetzt, sie wird verantwortungsvoll eingesetzt.
Die Euphorie ist groß – und berechtigt. Aber jede technische Revolution bringt auch Fragen mit sich, die unbequemer sind als jede Produktdemo: Nur weil wir es können – sollten wir es auch tun? Die enormen Fortschritte generativer Künstlicher Intelligenz in den letzten Jahren basieren auf dem Training mit riesigen Datenmengen. Genau dort liegt ein bedeutender ethischer Schwachpunkt. Die überwiegende Mehrheit aller KI-Dienste bergen das Risiko, dass sensible Informationen ungewollt Eingang in das Training finden und auch wieder nach außen gelangen. Zwei spektakuläre Vorfälle im Jahr 2025 unterstreichen diese Besorgnis und zeigen, wie schnell Datenschutz‑Probleme entstehen können und warum sie für die Entwickler:innen und die Nutzer:innen von zentraler Bedeutung sein sollten.
Die Schattenseite – Wie zwei Vorfälle das Vertrauen erschüttern
Der Sommer 2025 könnte als ein Wendepunkt in der Geschichte der künstlichen Intelligenz gelten – nicht wegen bahnbrechender technischer Innovationen, sondern aufgrund zweier Enthüllungen, die das Vertrauen in KI-Systeme nachhaltig erschüttert haben oder besser sollten. Am 30. Juli deckte das US-Magazin Fast Company [1] auf, dass über 110.000 private Gespräche mit ChatGPT über eine einfache Google-Suche auffindbar waren. Grund hierfür war eine irreführende, inzwischen deaktivierte Teilen-Funktion von Chatverläufen, durch die nicht nur ein Link zum Teilen erzeugt, sondern auch die Freigabe an Google akzeptiert wurde. [2] Viele Nutzer:innen gingen davon aus, dass hierdurch das Gespräch in ihrem eigenen Account gespeichert wird. Es fehlte jedoch ein klarer Hinweis darauf, dass das jeweilige Gespräch dadurch von den internen Crawlern von OpenAI erfasst und anschließend von Google indexiert und öffentlich zugänglich wurde. Auch ein einfacher Opt‑Out‑Mechanismus war nicht vorhanden – selbst wenn das Kästchen deaktiviert wurde, blieb das Gespräch zunächst in einer Zwischenspeicherung, die von den Crawlern erfasst werden konnte. Die Folgen waren gravierend: Personen, die vertrauliche medizinische Fragen stellten, CEOs, die interne Unternehmensstrategien teilten, oder ein italienischer Anwalt, der über heikle politische Themen diskutierte, sahen ihre Aussagen plötzlich im Internet. Neben dem offensichtlichen Vertrauensverlust führte das Ereignis zu zahlreichen rechtlichen Auseinandersetzungen, da die betroffenen Nutzer:innen argumentierten, dass ihre Daten ohne ausdrückliche Einwilligung veröffentlicht worden seien.
Der Vorfall macht deutlich, dass ein schlechtes UI‑Design und fehlende Transparenz allein schon ausreichen, um massive Datenschutzverletzungen zu verursachen.
Dass dieser Vorfall scheinbar nur die sichtbare Spitze eines alarmierenden Systemversagens ist, enthüllte eine bereits am 20. Juni veröffentlichte Studie [3] eines Forschungsteams der University of Washington. Die Forschenden analysierten den sogenannten DataComp CommonPool – einen der größten öffentlich verfügbaren Bilddatensätze mit 12,8 Milliarden Bild-Text-Paaren, die zwischen 2014 und 2022 aus dem Internet extrahiert wurden. Dieser Datensatz wird seit mehreren Jahren weltweit in der Wissenschaft und in der Wirtschaft zum Trainieren von Bild‑ und Video‑Modellen genutzt. Obwohl die Datensätze zuvor einer Reihe von Anonymisierungs‑Schritten unterzogen worden waren, fand das Forschungsteam in diesem Datensatz zahlreiche hochsensible Informationen wie Gesichter, Fahrzeugkennzeichen, GPS‑Koordinaten und andere Metadaten. Einige Fotos zeigten sogar private Wohnsituationen, medizinische Geräte oder andere Details, die eindeutig einer einzelnen Person zugeordnet werden konnten. Zusammengefasst fanden sie in ihrer Analyse von nur 0,1 Prozent des Datensatzes:
- Mindestens 102 Millionen nicht verwischte Gesichter echter Menschen
- Über 142.000 Lebensläufe mit verifizierbarer Online-Präsenz der betroffenen Personen
- Tausende Identitätsdokumente: Führerscheine, Pässe, Sozialversicherungsnummern und Kreditkarten mit Sicherheitscodes
- Bilder und medizinische Aufzeichnungen von Kindern sowie deren Geburtsurkunden.
Der Grund lag in einer unzureichenden Qualitätskontrolle: Das Team, das den Datensatz zusammenstellte, hatte zwar Privatsphäremaßnahmen implementiert (z. B. Gesichtsverpixelung, Opt-Out-Funktionen), diese wurden aber nicht evaluiert oder auditiert, bevor das Dataset veröffentlicht wurde. Zudem waren viele der Bilder unter restriktiven Lizenzen veröffentlicht, deren Weiterverwendung nicht erlaubt war – das wurde in der Dokumentation zur Verwendung des Datensatzes nicht klar ausgewiesen. Somit war auch die Dokumentation nicht nur unvollständig, sondern besaß darüber hinaus nur Freiwilligkeits-Charakter. [3]
Die massenhafte Erhebung privater Daten für KI-Trainingszwecke findet somit seit Jahren in einem unüberblickbaren Ausmaß mit weitreichenden Konsequenzen auch für die Wissenschaft statt. Forschende, die den CommonPool bereits in ihren Modellen verwendet hatten, sahen sich plötzlich mit der Gefahr konfrontiert, dass ihre Systeme unbeabsichtigt persönliche Daten tausender Menschen reproduzieren könnten. Gleichzeitig löste die Studie eine Debatte darüber aus, wie offene Forschungsdaten bereitgestellt werden dürfen, ohne die Privatsphäre von Einzelpersonen zu gefährden. Um dieses Problem zu adressieren, wäre grundsätzlich ein verpflichtender Datenschutz-Compliance-Prozess nötig, der wie in der beistehenden Grafik beispielhaft dargestellt gestaltet werden könnte.
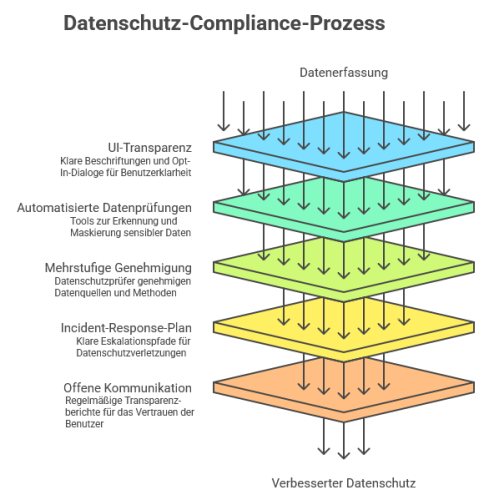
erstellt mit Napkin.AI
Allein die beiden erläuterten Datenschutzverstöße zeigen, dass schon die Akquisemethoden und die Weiterverarbeitung von persönlichen Daten hierzulande nicht nur ethische Fragen aufwerfen, sondern gegen geltendes Recht verstoßen. Auch für Unternehmen, die als Anbieter oder „nur“ als Betreiber (Artikel 3 Nr. 3 KI-VO) agieren, könnten die auf diese Weise gewonnenen und verarbeiteten Daten erhebliche rechtliche Konsequenzen haben. Diesbezüglich gilt im EU-Rechtsraum eine besondere Sorgfaltspflicht, welche mit der Datenschutzgrundverordnung (DSGVO) sowie mit der KI-Verordnung einen ersten rechtlichen Rahmen erhalten hat. Zur Vertiefung empfehlen wir einen Gastbeitrag von Christoph Möx (Kanzlei Bette Westenberger Brink Rechtsanwälte) und Sarah Tavčer (RMPrivacy GmbH) auf der Internetseite des Mittelstand-Digital Zentrums Ilmenau: https://www.zentrum-ilmenau.digital/gastbeitrag-regulierung-der-ki/.
Doch damit nicht genug. Das Thema Datenschutz reicht weit über die Akquise von Daten hinaus. Denn selbst wenn Daten rechtskonform erworben wurden, gibt es eine Vielzahl an Stolpersteinen für weitere Datenschutzverstöße. In der beigefügten Grafik wurde versucht, das Themenfeld möglichst umfassend darzustellen, um gerade bei der Nutzung von Diensten generativer KI wie ChatGPT für einen veränderten Umgang zu sensibilisieren. Dass dies dringend nötig ist, haben die beiden Beispiele zu Beginn gezeigt. Aber können derzeit verfügbare Sprachmodelle überhaupt DSGVO-konform sein?
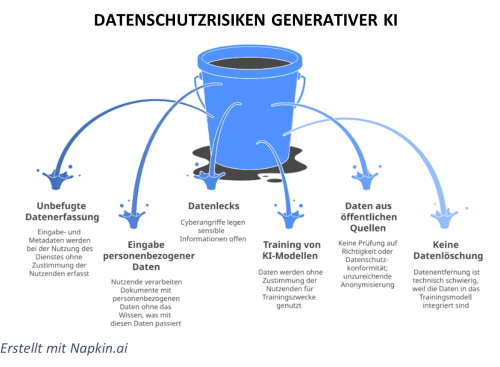
Ein anonymes LLM ist bisher eine Illusion
Die Bundesbeauftragte für den Datenschutz (BfDI) Prof. Dr. Specht-Riemenschneider hat in diesem Jahr im Zuge einer Konsultation die grundsätzliche Frage gestellt, ob personenbezogene Daten beim Einsatz von Large-Language-Modellen (LLMs) überhaupt geschützt werden können. Die Gesellschaft für Informatik (GI) antwortet im Klartext: „Anonyme KI‑Modelle sind derzeit technisch eine Illusion.“ [4] Dieses Urteil beruht auf den Kernprinzipien der Datenschutzgrundverordnung (DSGVO):
- Art. 5 Abs. 1 c fordert Datenminimierung – nur jene Daten dürfen verarbeitet werden, die für den jeweiligen Zweck unbedingt nötig sind. LLM‑Training benötigt jedoch massive Textkorpora, in denen personenbezogene Informationen häufig vorkommen. Selbst wenn nachträgliche Anonymisierungstechniken angewendet werden, können aktuelle Verfahren nicht garantieren, dass kein einzelner Prompt später sensible Fakten preisgibt.
- Art. 7 Abs. 4 verlangt eine einwilligungsbasierte Verarbeitung für jeden Verwendungszweck. Da Anbieter wie OpenAI nicht offenlegen können, welche konkreten Daten im Modell gespeichert sind, ist eine informierte Einwilligung praktisch unmöglich. Die GI fordert deshalb gesetzliche Dokumentations‑ und Fehlerbehebungspflichten (vgl. Art. 24 Abs. 1), damit Unternehmen nachvollziehen können, wann und wie ein Datenleck entsteht, um sofort reagieren zu können.
- Ein weiteres Risiko ergibt sich aus Art. 32 Abs. 1, der Sicherheitsmaßnahmen verlangt. LLMs erzeugen Ausgaben anhand von Wahrscheinlichkeiten; dadurch können Falschinformationen entstehen, die Personen fälschlicherweise bestimmte Tatsachen zuschreiben und ihren Ruf schädigen können. Laut GI sind solche Fehler bereits eingetreten und stellen einen klaren Verstoß gegen das Prinzip der Integrität und Vertraulichkeit dar.
Die DSGVO verlangt zusammengefasst für jede Datenverarbeitung Transparenz, Kontrolle und Sicherheit. Während das Training von LLMs bereits schwer zu überprüfen ist, liegt ein großer Teil des Risikos in der Inferenz‑Phase – also dem eigentlichen Chat‑Dialog. Hier entstehen Logs, Nutzerprofile und die potenzielle Weitergabe von Eingaben an Trainingspipelines. Ein wirklich DSGVO‑konformes Inferenz‑Modell muss diese Praktiken konsequent ausschließen oder zumindest streng regulieren. Glauben Sie, dass es das bereits gibt?
DSGVO-konforme Inferenz-Modelle – ein realistischer Ausblick
In der Europäischen Union existieren aktuell mehrere Chat‑Engines, die die strengen Vorgaben von DSGVO und AI‑Act (KI-VO der Europäischen Union) bereits in ihrer Architektur verankern. Eine Auswahl empfohlener Dienste und technische Hinweise zur Datenschutzkonformität findet sich in folgender Tabelle.
| Dienst | DSGVO-Konformität in der Inferenz |
| Lumo (Proton) | •Zero-Log-Policy – Eingaben werden nach maximal 30 Tagen automatisch gelöscht, sofern keine gesetzlichen Aufbewahrungspflichten bestehen.
• Opt-Out-Standard – Daten werden niemals für das weitere Modell Training verwendet, es sei denn, der Nutzer aktiviert explizit eine Einwilligung. • Ende-zu-Ende-Verschlüsselung schützt die Kommunikation vor Dritten; Schlüssel liegen ausschließlich beim Endgerät. |
| Apertus | • Selective Retention – Nur Metadaten (Zeitstempel, SessionID) werden kurzzeitig gespeichert; Inhalte werden nach jeder Sitzung verworfen.
• Transparent-Consent-Layer zeigt dem Nutzer sofort, ob seine Eingabe zum Training beiträgt; Standard ist „Nein“. • On-Device-Inference (optional) ermöglicht, dass das Modell lokal läuft, wodurch keinerlei Netzwerk-Traffic entsteht. |
| Claude by Anthropic (EUHosting) | • Data Usage Control – Kunden können das Feature “No Learning Mode” aktivieren; dann werden keinerlei Prompt-Daten in das globale Trainingsset eingespeist.
• Audit-Logs werden nur für Sicherheits- und Fehlermanagementzwecke gespeichert und nach 7 Tagen gelöscht. • Privacy-First-Architecture trennt strikt Nutzer Sessions, sodass keine Profilbildung über mehrere Chats hinweg möglich ist. |
Die offene Code‑Basis von Apertus erleichtert Audits, weil der Quellcode öffentlich einsehbar ist. Dadurch können unabhängige Sicherheitsexpertinnen, Forschungseinrichtungen oder interne Auditor:innen den Quellcode prüfen, Schwachstellen identifizieren und nachweisen, dass Datenschutz‑Mechanismen wie Daten‑Minimierung, Verschlüsselung und die Speicherdauerbegrenzung von Log-Dateien korrekt implementiert sind. Die Transparenz des Open‑Source‑Ansatzes ermöglicht zudem durch Protokollierung eine schnelle Nachvollziehbarkeit von Änderungen.
Im Gegensatz dazu basieren die geschlossenen Modelle Lumo (Proton) und Claude (Anthropic) auf proprietärem Quellcode, der nicht öffentlich verfügbar ist. Um die fehlende Quellcode‑Transparenz zu kompensieren, setzen diese Anbieter auf anerkannte externe Zertifizierungen (ISO 27001, GDPR‑Ready‑ bzw. Datenschutz‑Zertifizierungen) und unabhängige Audits. Damit gewährleisten alle drei Systeme ein hohes Maß an Nachvollziehbarkeit und Vertrauen, obwohl die jeweiligen Ansätze unterschiedliche Wege zur Sicherstellung der Datenschutz‑ und Sicherheitsanforderungen wählen.
Fazit
Die Entwicklungen des Jahres 2025 verdeutlichen, dass Datenschutz im Kontext generativer KI an zwei sehr unterschiedlichen, aber gleichermaßen kritischen Stellen gefährdet ist: beim Training der Modelle und bei der Nutzung der Dienste. Die beiden Beispiele zeigen, dass Datenschutzverstöße nicht nur aus technischen Schwächen, sondern vor allem aus fehlenden Standards, mangelnder Prüfpflicht und unklaren Verantwortlichkeiten resultieren.
Auf der Trainingsseite ermöglichte die Offenlegung des unzureichend kuratierten CommonPool-Datensatzes, der massenhaft sensible Informationen enthielt, ein Hinweis darauf, dass bestehende Anonymisierungs- und Kontrollmechanismen bei Weitem nicht ausreichen. Solange Modelle mit riesigen, kaum überprüfbaren Datenpools entwickelt werden, bleibt das Risiko bestehen, dass personenbezogene Inhalte im Modell verankert werden oder unbeabsichtigt reproduziert werden können.
Auf der Nutzungsseite wiederum offenbaren die veröffentlichten Chatverläufe von 2025, wie schnell auch „harmlose“ Designfehler, fehlende Transparenz oder unklare Opt-Out-Mechanismen zu massiven Datenschutzverletzungen führen. Selbst wenn ein Modell korrekt trainiert wurde, können unzureichend gesicherte Inferenzsysteme vertrauliche Nutzereingaben kompromittieren.
Gleichzeitig gibt es ermutigende Entwicklungen: Erste Anbieter beweisen, dass eine datenschutzfreundliche Nutzung von KI-Modellen möglich ist – wenn Transparenz, Datenminimierung und technische Sicherheitsmaßnahmen von Anfang an mitgedacht werden. Entscheidend ist daher nicht, ob wir KI nutzen, sondern wie wir sie gestalten. Nur wenn Datenschutz, Verantwortlichkeit und klare Standards fest verankert werden, kann künstliche Intelligenz langfristig Vertrauen schaffen und sicher zum Wohl der Gesellschaft eingesetzt werden. Eine grundsätzliche Voraussetzung dafür bleibt jedoch das Bewusstsein für den sensiblen Umgang mit Daten.
Quellen:
[1] https://www.fastcompany.com/91376687/google-indexing-chatgpt-conversations
[2] https://www.netzwelt.de/news/244940-wegen-verwirrende-teilen-funktion-tausende-chatgpt-gespraeche-via-google-auffindbar.html
[3] https://arxiv.org/abs/2506.17185?trk=article-ssr-frontend-pulse_little-text-block
[4] https://gi.de/meldung/gi-beantwortet-fragen-der-datenschutzbeauftragten-zu-llms
Ansprechpartner:
Karsten Jahn
KI-Trainer Modellfabrik Virtualisierung
Telefon: 03641/205295
E-Mail: jahn@kompetenzzentrum-ilmenau.de
Bildquellen
- Datenleck: KI-generiert mit Microsoft Copilot



